Comment gagner de l'argent grâce à Donald Trump (et au web scraping) en 2026 ?
C'est la nouvelle donne sur les marchés financiers. Le président Donald Trump fait trembler le monde (et votre portefeuille) à chaque publication sur son réseau social Truth Social. Je vous montre ici comment scraper truthsocial.com et utiliser les pouvoirs de l'IA pour savoir avant tout le monde.
Disclaimer : Cet article est publié à des fins éducatives et de recherche uniquement. Il ne constitue pas un conseil en investissement.
Votre temps est précieux, alors allons-y !
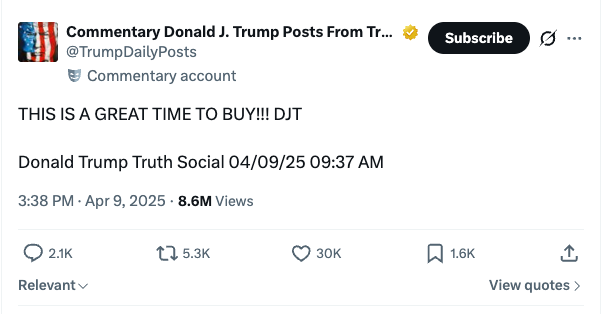
On se souvient tous du post de DJT le 9 avril 2025 à 9h37 (heure de New York) :
"THIS IS A GREAT TIME TO BUY!!! DJT"
Quelques heures plus tard, les marchés explosaient à la hausse.
On a beaucoup parlé du Trump trading.
Le principe est simple :
Suivre ce que dit Trump → prendre position → empocher les gains.
Les mouvements de marchés sont violents, historiques même.
D'ici la fin de son mandat, Donald J. Trump continuera, à coup sûr, de faire bouger les marchés.
La vraie question est donc :
Comment être alerté en premier la prochaine fois ?
Retour sur le cas du 9 avril 2025
📉 Début avril 2025, les marchés plongent après l'annonce de droits de douane massifs (~5 000 Md$ effacés en 48h).
📱 Le 9 avril à 9h37, Trump publie "THIS IS A GREAT TIME TO BUY!!!" sur Truth Social.
⏳ Quelques heures plus tard, pause de 90 jours sur les tarifs.
🚀 Résultat en clôture : S&P +9,5% · Nasdaq +12% · crypto en rally parallèle.
Un post. Une décision. Un mouvement historique.
👉 Ce qui nous intéresse ici, ce n'est pas la finance — c'est la donnée.
Ce que ce cas révèle : un problème d'ingestion de données en temps réel
Alors comment faire ?
- publication sur turthsocial.com
- collecte de la données
- analyse des données -> quel marché ? acheter ? vendre ?
Premièrement, il nous faut la données en temps réel. Et pour une fois, pas besoin d'être un hedge fund, pas besoin d'être Warren Buffet. Un ordinateur, un développeur, un expert en scrping, et c'est parti. 🚀
Pour ne rien rater, il faut scraper Truth Social en continu, fréquemment. Pas de webhook, pas de stream, pas de push : la seule option est le polling haute fréquence. Celui qui a le pipeline le plus rapide lit le signal en premier.
Pourquoi les publications de Trump font bouger les marchés
Depuis le retour de Donald J Trump, les marchés ont intégré une nouvelle réalité :
La politique économique américaine se communique aussi sur les réseaux sociaux.
Et pas n'importe lequel. Trump publie en priorité sur Truth Social — le réseau social qu'il a lui-même fondé, et qui est devenu le canal officiel de communication du président des États-Unis. Pas X, pas Facebook : Truth Social est le premier endroit où ses annonces apparaissent.
Truth Social est à surveiller en priorité. Ce que Trump y publie a valeur de déclaration officielle.
Chaque publication peut impacter :
- les actions
- les monnaies
- les cryptomonnaies
- les matières premières
- les taux d'intérêt
- les marchés dérivés
Résultat :
Les desks macro, hedge funds, traders et analystes surveillent désormais Truth Social comme la source d'information stratégique numéro un sur la politique économique américaine.
Le problème : l'information arrive trop tard
Surveiller Truth Social manuellement pose plusieurs limites majeures :
- Pas d'API publique officielle
- Notifications peu fiables
- Surveillance humaine impossible 24/7
- Latence entre publication et lecture
- Aucun parsing ni extraction de données structurée exploitable
Market timing is crucial.
La solution : scraper Truth Social en temps réel
Le web scraping permet d'automatiser ce que l'humain ne peut pas faire manuellement : surveiller une source 24h/24, extraire chaque nouvelle donnée rapidement, et déclencher une action immédiate.
Appliqué à Truth Social, le scraping de données financières donne ceci :
- détecter chaque nouveau post en temps réel,
- extraire et structurer automatiquement le contenu,
- analyser les news -> achter ? vendre ? quel marché ?
Autrement dit :
Transformer un réseau social politique en flux de données financières exploitables grâce au web scraping.
Tutoriel : scraper Truth Social étape par étape (Python)
On va construire le scraper web ensemble, bloc par bloc.
À la fin de ce tutoriel, vous aurez un script Python fonctionnel qui :
- scrape les derniers posts de @realDonaldTrump en temps réel,
- extrait et structure les données automatiquement (texte, date, engagement),
- détecte les posts à potentiel financier via une analyse de mots-clés,
- affiche tout dans un terminal avec un formatage lisible.
Prérequis
pip install curl_cffi
Pourquoi curl_cffi et pas requests ?
Truth Social est protégé par Cloudflare. Une requête classique avec requests sera bloquée instantanément.
curl_cffi résout ce problème : il reproduit le handshake TLS d'un vrai navigateur Chrome (même JA3 fingerprint). Cloudflare voit un Chrome légitime, pas un bot Python.
Étape 1 — Comprendre l'API
Truth Social est basé sur Mastodon, un logiciel open-source.
L'API Mastodon est documentée et prévisible. Pour récupérer les posts d'un compte, il suffit de connaître son account ID :
GET /api/v1/accounts/{account_id}/statuses
L'account ID de @realDonaldTrump est 107780257626128497.
On peut le retrouver facilement : ouvrez le profil dans votre navigateur, inspectez les requêtes réseau (onglet Network dans DevTools), et cherchez un appel à /api/v1/accounts/.
Pourquoi les anti-bots sont devenus un vrai sujet d'ingénierie
Cloudflare n'est pas un simple captcha. C'est un système d'analyse comportementale et de fingerprinting qui opère à plusieurs niveaux simultanément.
Au niveau TLS d'abord : chaque client HTTP a une signature unique — l'ordre des cipher suites, les extensions TLS, les courbes elliptiques supportées. requests en Python a un JA3 fingerprint reconnaissable immédiatement. Cloudflare le compare à sa base de signatures connues. Si ça ne ressemble pas à un vrai Chrome, la requête est bloquée ou challengée avant même d'avoir regardé l'URL.
Au niveau HTTP/2 ensuite : l'ordre des frames, les valeurs de SETTINGS, les priorités de stream — tout ça forme une empreinte supplémentaire. Un vrai Chrome sur HTTP/2 se comporte d'une façon très précise que les bibliothèques HTTP standard ne reproduisent pas.
Enfin au niveau applicatif : les cookies cf_clearance et __cf_bm sont des jetons cryptographiques signés qui attestent qu'un challenge JavaScript a été résolu dans un vrai navigateur. Ils ont une durée de vie limitée et sont liés à l'IP source.
curl_cffi résout les deux premiers niveaux par impersonation. Pour le troisième niveau — la gestion des sessions et le renouvellement des cookies — il faut soit maintenir une session navigateur headless (Playwright), soit utiliser une infrastructure de scraping qui gère ça de façon industrielle.
En production, c'est le principal défi opérationnel : maintenir des sessions valides, à haute fréquence, sans se faire bannir. Ce n'est plus de la programmation, c'est de la gestion d'infrastructure.
Étape 3 — Configurer les headers HTTP
Les headers doivent être cohérents avec un vrai navigateur. Pas besoin de tout mettre — curl_cffi génère automatiquement les headers Chrome (User-Agent, sec-ch-ua, etc.) grâce à l'impersonation.
On ajoute seulement les headers spécifiques à l'API :
headers = {
# On veut du JSON, pas du HTML
'accept': 'application/json, text/plain, */*',
'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7',
# Anti-cache pour toujours avoir les derniers posts
'cache-control': 'no-cache',
'pragma': 'no-cache',
# Headers Sec-Fetch — indiquent un appel AJAX depuis le site
'referer': 'https://truthsocial.com/@realDonaldTrump/',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
}
Et les paramètres de requête :
params = {
'exclude_replies': 'true', # On ne veut que les posts, pas les réponses
'only_replies': 'false',
'with_muted': 'true',
}
Étape 4 — Faire la requête avec curl_cffi
C'est la pièce maîtresse. On crée une session avec impersonation Chrome :
from curl_cffi import requests
IMPERSONATE = "chrome"
ACCOUNT_ID = "107780257626128497"
API_URL = f"https://truthsocial.com/api/v1/accounts/{ACCOUNT_ID}/statuses"
session = requests.Session(impersonate=IMPERSONATE)
response = session.get(
API_URL,
params=params,
cookies=cookies,
headers=headers,
timeout=30,
)
posts = response.json()
impersonate="chrome" fait tout le travail : le handshake TLS, le HTTP/2, les headers par défaut — tout est identique à un vrai Chrome.
L'API retourne une liste de posts au format JSON (standard Mastodon).
Étape 5 — Parser le contenu HTML
Le contenu des posts est en HTML (<p>, <br/>, <a>, etc.). On le convertit en texte lisible :
import re
from html import unescape
_HTML_TAG = re.compile(r"<[^>]+>")
def strip_html(raw: str) -> str:
# Convertir les balises de saut de ligne en \n
text = raw.replace("<br/>", "\n").replace("<br>", "\n").replace("</p><p>", "\n\n")
# Supprimer toutes les autres balises HTML
text = _HTML_TAG.sub("", text)
# Décoder les entités HTML (& → &, etc.)
text = unescape(text)
return text.strip()
Étape 6 — Détecter les posts financièrement sensibles
Dans le script, on a mis en place une fonction detect_financial() qui scanne chaque post par mots-clés (tariff, market, nasdaq, etc.). C'est suffisant pour un prototype, mais limité : la détection par mots-clés ne comprend pas le contexte.
En production, il faut brancher ça à un LLM (Claude, OpenAI, Mistral…) pour obtenir une vraie analyse : sentiment, actifs concernés, urgence, action recommandée. Le LLM transforme un post brut en signal structuré et interprété, pas juste un flag binaire.
Intégrer les alertes : Telegram, WhatsApp, bots de trading
Une fois le signal généré, il faut le livrer instantanément là où vous êtes.
Alerting temps réel :
- Telegram Bot — le plus simple à mettre en place, une API REST, notification push immédiate sur mobile
- WhatsApp — via l'API Cloud de Meta ou des services tiers (Twilio, CallMeBot)
- Discord webhook — idéal pour les communautés de traders
- Email / SMS — pour les alertes critiques uniquement (latence plus haute)
Connexion à un bot de trading :
- Relier le signal à CCXT (bibliothèque Python qui connecte 100+ exchanges crypto) pour passer des ordres automatiquement
- Envoyer le signal à TradingView via webhook pour déclencher une stratégie Pine Script
- Intégrer avec Interactive Brokers ou Alpaca pour les marchés actions
Le schéma complet ressemble à ça :
Truth Social post
↓
Scraper (curl_cffi)
↓
LLM (analyse du signal)
↓
Signal structuré { sentiment, actifs, urgence }
↓
┌─────────────┬──────────────┬─────────────┐
Telegram Discord Bot de trading
push webhook (CCXT / Alpaca)
C'est ce pipeline complet — du scraping à l'ordre de trading automatisé — qui fait la différence entre regarder les marchés bouger et en profiter en premier.
Étape 7 — Assembler et exécuter
On assemble le tout. Le script principal fait la requête, parse les posts, et affiche le résumé :
session = requests.Session(impersonate=IMPERSONATE)
response = session.get(
API_URL,
params=params,
cookies=cookies,
headers=headers,
timeout=30,
)
if response.status_code != 200:
print(f"ERR HTTP {response.status_code}")
raise SystemExit(1)
posts = response.json()
financial_count = 0
for i, post in enumerate(posts, 1):
source = post["reblog"] if post.get("reblog") else post
text = strip_html(source.get("content", ""))
if detect_financial(text):
financial_count += 1
print_post(post, i)
print(f"\n SUMMARY: {len(posts)} posts | {financial_count} market-relevant\n")
Lancez le script :
python3 main.py
Les posts financièrement sensibles apparaissent immédiatement avec un bandeau rouge FINANCIAL, les mots-clés détectés, et les métriques d'engagement.

Résultat : structure JSON brute d'un post
Chaque post retourné par l'API a cette structure (simplifiée) :
{
"id": "116086782319939311",
"created_at": "2026-02-17T15:55:24.364Z",
"content": "<p>Maryland, Virginia, and Washington, D.C., ...</p>",
"url": "https://truthsocial.com/@realDonaldTrump/116086782319939311",
"replies_count": 1694,
"reblogs_count": 4731,
"favourites_count": 17902,
"account": {
"username": "realDonaldTrump",
"display_name": "Donald J. Trump",
"followers_count": 11723542
},
"reblog": null,
"media_attachments": [],
"language": "en"
}
Et ensuite ? Passer le scraper en production
Ce script Python de web scraping est une base fonctionnelle. Pour passer en mode production et automatiser l'extraction de données financières en continu, il reste à ajouter :
- Polling en boucle — relancer le scraper toutes les X secondes, comparer les IDs de posts pour détecter les nouveaux
- Alerting — envoyer un webhook (Discord, Telegram, Slack) dès qu'un post financier est détecté
- Rotation de cookies — automatiser le renouvellement avec un navigateur headless (Playwright, Puppeteer)
- Rotation de proxies — contourner le rate-limiting sur des crawls haute fréquence
- Stockage structuré — sauvegarder chaque post extrait en base de données (SQLite, PostgreSQL) pour analyse historique et backtesting
C'est exactement ce que fait CrawlerGrid en production : un pipeline complet de scraping, d'extraction de données et d'alerting en temps réel.
Résumé : toutes les étapes du scraper
| Étape | Ce qu'on fait | Pourquoi |
|---|---|---|
| 1 | Identifier l'API Mastodon | Truth Social expose une API REST standard |
| 2 | Récupérer les cookies Cloudflare | Contourner l'anti-bot pour le scraping |
| 3 | Configurer les headers HTTP | Cohérence avec un vrai navigateur |
| 4 | curl_cffi + impersonate Chrome | TLS fingerprint identique à Chrome |
| 5 | Extraction et parsing du HTML | Données brutes → texte structuré exploitable |
| 6 | Détection par mots-clés financiers | Filtrer les posts market-relevant |
| 7 | Affichage couleur en terminal | Monitoring visuel temps réel |
| 8 | Assembler et exécuter | Scraper fonctionnel en < 200 lignes de Python |
Un post de Trump. Une requête de web scraping. Un signal de trading avant tout le monde.

Note : Cet article est un cas pratique d'ingénierie des données appliquée au scraping de sources ouvertes. Il ne constitue pas un conseil en investissement. L'objectif est de montrer comment construire une infrastructure d'extraction et d'ingestion de données en temps réel à partir d'une source non structurée et protégée par un WAF — la source en question se trouve juste être celle qui bouge le plus les marchés en ce moment.